Assignment 6
11 May 2017
Geog 370
Part I
Using the linear regression tool in SPSS, it is possible to determine the regression equation for the independent variable: Crime Rate, and the dependent variable: Percent of Kids that get Free Lunches.
The regression tool gives an R Squared value of .173. This means that only 17.3% of Percent of Kids that get Free Lunches can be explained by crime rate.
The Coefficient table, shown below, can be used to create the regression equation for the given data.

The regression equation is Y= 40.380 + .102 X
Y = percent of kids that get free lunch
X = Crime Rate
If a new area of town was identified as having 23.5% of kids with free lunch, the equation can be used to determine Crime Rate
23.5= 40.380 + .102 X --> .102X= -16.88 --> X= -165.49
Obviously crime rate cannot be a negative number. The reason this result is not accurate is because the R squared value is so low. Therefore there is little confidence in these results. There is, however, a significant value below .05 meaning there is a relationship. the relationship is also positive.
Part II
The goal for this part of the assignment is to locate the best location to build an ER room based on where the most 911 calls occur
Step 1
3 independent variables that will be analyzed using to regression analysis to determine if there is a relationship between them and 911 calls are:
Low Education
R squared= .567

For every unit of increased LowEduc there is a .116 increase in 911 calls.
Unemployed
R squared= .543
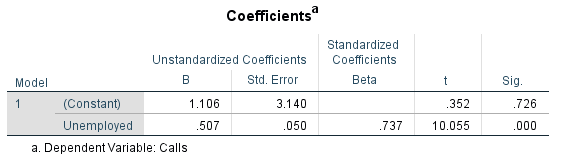
For every unit of increased Unemployed there is a .507 increase in 911 calls.
Median Income
R squared= .163

For every unit of increased MedIncome there is a -.001 decrease in 911 calls.
Step 2

The map above shows the number of 911 calls in each county

The map above shows how much 911 calls are correlated to Low Education spatially.The red areas are locations where the actual values are larger than the model estimated. The blue areas are locations where the actual values are smaller than the model estimated.
Part 3
Using SPSS it is possible to run a Collinearity Diagnostics test to see if there is Multicollinearity. The results are below.


Above is the results of the coefficients after running a stepwise regression analysis. Looking at the beta, LowEduc has the highest results, meaning that the average amount the 911 calls increases the most when the LowEduc variable increases one standard deviation and the other independent variables are held constant.
*Already created above is the residual map for LowEduc
(just by chance)
Step 4
After looking at these results, the best place to build an ER room would be in the northwest part of the county. This is because this is where the most calls seem to occur, also because this is where the lowest education of the county is found, allowing the planners to infer that there will be more calls from this area, now that they have been proven this is the most influential variable.